import numpy as np
data = np.genfromtxt("beispiel.csv", delimiter=",", skip_header=1)
print(data)[[ 21.1 45. 400. ]
[ 22.5 nan 420. ]
[ nan 50. 410. ]
[ 20. 48. nan]
[ 23.3 47. 430. ]]In dieser Einheit lernen Sie, wie man reale Messdaten – etwa aus Experimenten oder Ingenieurprojekten – mit NumPy und Matplotlib verarbeitet und analysiert. Der Fokus liegt dabei auf einem praxisnahen Umgang mit Daten im CSV-Format.
Sie lernen in dieser Einheit:
CSV-Dateien („Comma Separated Values“) sind weit verbreitet – etwa für:
Zu Beginn wird ein Beispiel betrachtet: Temperatur, Luftfeuchtigkeit und CO₂-Werte. Diese Datei enthält auch einige fehlende Werte, wie sie in realen Daten oft vorkommen.
import numpy as np
data = np.genfromtxt("beispiel.csv", delimiter=",", skip_header=1)
print(data)[[ 21.1 45. 400. ]
[ 22.5 nan 420. ]
[ nan 50. 410. ]
[ 20. 48. nan]
[ 23.3 47. 430. ]]Fehlende Werte werden beim Einlesen als np.nan (Not a Number) codiert. Zunächst wird gezählt, wie viele Werte fehlen:
print(np.isnan(data).sum(axis=0))[1 1 1]Um die Analyse nicht zu verfälschen, werden sie ersetzt – z. B. durch den Mittelwert der Spalte:
for i in range(data.shape[1]):
mean = np.nanmean(data[:, i])
data[:, i] = np.where(np.isnan(data[:, i]), mean, data[:, i])Typische Kennwerte zur Beschreibung von Daten:
print("Mittelwerte:", np.mean(data, axis=0))
print("Standardabweichung:", np.std(data, axis=0))Mittelwerte: [ 21.725 47.5 415. ]
Standardabweichung: [ 1.13556154 1.61245155 10. ]Mit Matplotlib lassen sich Daten übersichtlich darstellen. Es werden z. B. Linien- und Histogrammplots genutzt.
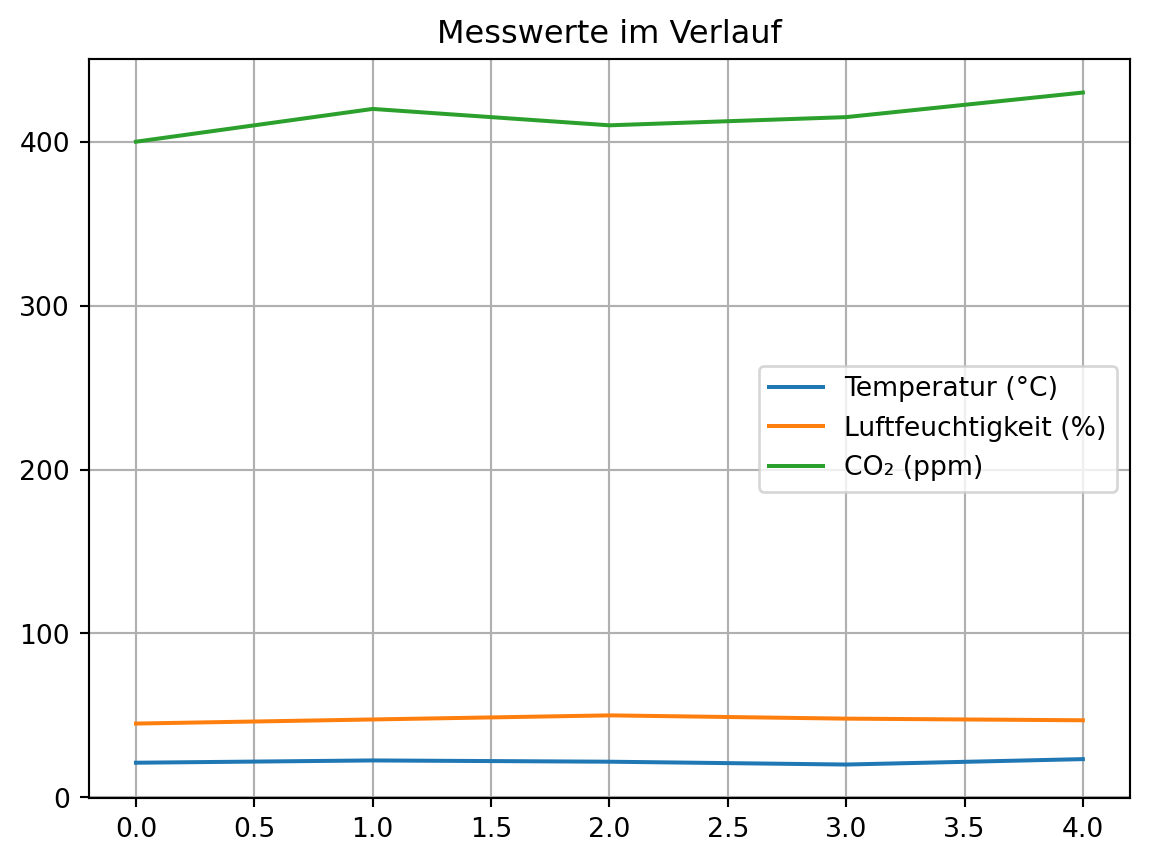
import matplotlib.pyplot as plt
labels = ["Temperatur (°C)", "Luftfeuchtigkeit (%)", "CO₂ (ppm)"]
for i in range(data.shape[1]):
plt.plot(data[:, i], label=labels[i])
plt.legend()
plt.title("Messwerte im Verlauf")
plt.grid(True)
plt.show()