2.10. Einwohnerzahl Europa#
Bei dieser Aufgabe werden Sie sowohl Schleifen als auch Verzweigungen nutzen, um Daten aus einer Datei auszulesen und in sinvolle Datentypen abzuspeichern. In der Bonusaufgabe werden Sie einen Filter auf die Daten anwenden und eine Berechnung mit ihnen durchführen.
Die in dieser Aufgabe verwendete Datei finden Sie hier.
Aufgabenteil A – Auslesen der Datei#
Schreiben Sie ein Programm, dass den Inhalt der Datei einwohner_europa_2019.csv ausließt und ausgibt.
Lösungsvorschlag#
Show code cell content
# Auslesen und Ausgeben einer Datei
file = open('einwohner_europa_2019.csv', 'r')
for line in file:
print(line)
GEO,Value
Belgien,11467923
Bulgarien,7000039
Tschechien,10528984
Daenemark,5799763
Deutschland einschliesslich ehemalige DDR,82940663
Estland,1324820
Irland,4904240
Griechenland,10722287
Spanien,46934632
Frankreich,67028048
Kroatien,4076246
Italien,61068437
Zypern,875898
Lettland,1919968
Litauen,2794184
Luxemburg,612179
Uganda,-1
Ungarn,9772756
Malta,493559
Niederlande,17423013
Oesterreich,8842000
Polen,37972812
Portugal,10276617
Rumaenien,19405156
Slowenien,2080908
Slowakei,5450421
Finnland,5512119
Schweden,10243000
Vereinigtes Koenigreich,66647112
Aufgabenteil B – Speichern in Listen#
Verändern Sie obiges Programm, sodass die ausgelesenen Daten nicht mehr ausgegeben, sondern in zwei Listen gespeichert werden. Die Erste Zeile soll hierbei ignoriert werden. Die Liste mit den Einwohnern soll Zahlen anstelle von Strings enthalten.
Lösungshinweis#
Benutzen Sie eine Bool-Variable um zu überprüfen, ob Sie gerade die erste Zeile der Datei auslesen. Alternativ können Sie mit der pop-Methode von Listen Elemente an einer bestimmten Position löschen.
Lösungsvorschlag I#
Show code cell content
# Auslesen einer Datei und Speichern in Listen
laender = []
bevoelkerungen = []
erste_zeile = True
file = open('einwohner_europa_2019.csv', 'r')
# Speichern der Datei in zwei Listen
for line in file:
# Überprüfung, ob das Programm gerade die erste Zeile der Datei ausließt
if not erste_zeile:
# Aufteilen der Zeile in zwei Variablen
[land, einwohner] = line.split(',')
# Konvertierung in einen Integer
einwohner = int(einwohner)
# Erweiterung der Listen um die beiden Elemente der aktuell ausgelesenen Zeile
laender.append(land)
bevoelkerungen.append(int(einwohner))
else:
erste_zeile = False
print(laender)
print(bevoelkerungen)
file.close()
['Belgien', 'Bulgarien', 'Tschechien', 'Daenemark', 'Deutschland einschliesslich ehemalige DDR', 'Estland', 'Irland', 'Griechenland', 'Spanien', 'Frankreich', 'Kroatien', 'Italien', 'Zypern', 'Lettland', 'Litauen', 'Luxemburg', 'Uganda', 'Ungarn', 'Malta', 'Niederlande', 'Oesterreich', 'Polen', 'Portugal', 'Rumaenien', 'Slowenien', 'Slowakei', 'Finnland', 'Schweden', 'Vereinigtes Koenigreich']
[11467923, 7000039, 10528984, 5799763, 82940663, 1324820, 4904240, 10722287, 46934632, 67028048, 4076246, 61068437, 875898, 1919968, 2794184, 612179, -1, 9772756, 493559, 17423013, 8842000, 37972812, 10276617, 19405156, 2080908, 5450421, 5512119, 10243000, 66647112]
Lösungsvorschlag II#
Show code cell content
# Auslesen einer Datei und Speichern in Listen
laender = []
einwohner = []
file = open('einwohner_europa_2019.csv', 'r')
# Speichern der Datei in zwei Listen
for line in file:
laender.append(line.split(',')[0])
einwohner.append(line.split(',')[1])
# Entfernen des ersten Elements beider Listen
laender.pop(0)
einwohner.pop(0)
# Konvertieren der Elemente in Einwohner in Integers
for i in range(0,len(einwohner)):
einwohner[i] = int(einwohner[i])
print(laender)
print(einwohner)
file.close()
['Belgien', 'Bulgarien', 'Tschechien', 'Daenemark', 'Deutschland einschliesslich ehemalige DDR', 'Estland', 'Irland', 'Griechenland', 'Spanien', 'Frankreich', 'Kroatien', 'Italien', 'Zypern', 'Lettland', 'Litauen', 'Luxemburg', 'Uganda', 'Ungarn', 'Malta', 'Niederlande', 'Oesterreich', 'Polen', 'Portugal', 'Rumaenien', 'Slowenien', 'Slowakei', 'Finnland', 'Schweden', 'Vereinigtes Koenigreich']
[11467923, 7000039, 10528984, 5799763, 82940663, 1324820, 4904240, 10722287, 46934632, 67028048, 4076246, 61068437, 875898, 1919968, 2794184, 612179, -1, 9772756, 493559, 17423013, 8842000, 37972812, 10276617, 19405156, 2080908, 5450421, 5512119, 10243000, 66647112]
Aufgabenteil C – Filtern und Verwenden – Optional#
Erweitern Sie Ihr Programm, sodass Länder, die eine negative Einwohnerzahl haben, aus beiden Listen gelöscht werden. Addieren Sie danach alle Einwohner, um die gesammte Einwohnerzahl aller EU-Staaten zu erhalten und geben sie das Ergebnis in Millionen aus.
Lösungshinweis#
Falls Sie beim Löschen auf einen out-of-range IndexError treffen, überlegen Sie sich, warum dies passiert und ob Sie vielleicht mit einer anderen Schleifenart das Problem umgehen können.
Lösungsvorschlag#
Show code cell content
# Auswerten von Daten
laender = []
einwohner = []
file = open('einwohner_europa_2019.csv', 'r')
# Speichern der Datei in zwei Listen
for line in file:
laender.append(line.split(',')[0])
einwohner.append(line.split(',')[1])
# Entfernen des ersten Elements beider Listen
laender.pop(0)
einwohner.pop(0)
# Konvertieren der Elemente in Einwohner in Integers
for i in range(0,len(einwohner)):
einwohner[i] = int(einwohner[i])
# Entfernen von Ausreißern
i = 0
while i < len(einwohner):
if einwohner[i] < 0:
einwohner.pop(i)
laender.pop(i)
i += 1
# Berechnung der gesammten EU-Bevölkerung
gesammtBev = 0
for i in einwohner:
gesammtBev += i
print(f'Die gesammte EU-Bevölkerung in 2019 waren ungefähr {gesammtBev/10**6:.2f} Millionen Personen.')
file.close()
Die gesammte EU-Bevölkerung in 2019 waren ungefähr 514.12 Millionen Personen.
Aufgabenteil D#
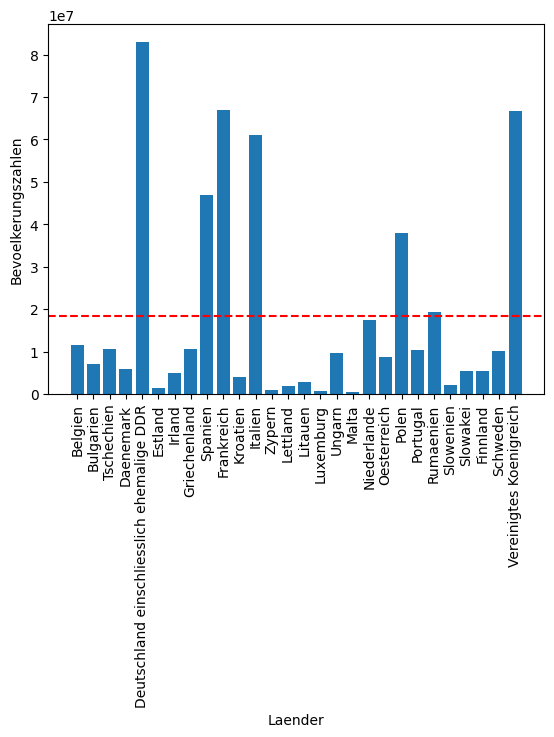
Plotten Sie nun die Bevölkerungszahlen (y-Achse) für die entsprechenden Länder (x-Achse). Fügen Sie Achsen-Beschriftungen hinzu. Berechnen Sie den Mittelwert aller Bevölkerungszahlen und Ploten Sie diesen als gestrichelte rote Linie. Hinweis:
Um die Ländernamen besser lesen zu können, soll die Beschriftung um 90 grad gedreht werden.
Wenn Sie plt.bar() anstelle von plt.plot() verwenden, erhalten Sie ein Balkendiagramm.
Lösungsvorschlag#
Show code cell content
import matplotlib.pyplot as plt
print(laender)
print(einwohner)
plt.bar(laender,einwohner)
plt.xlabel("Laender")
plt.ylabel("Bevoelkerungszahlen")
plt.axhline(gesammtBev/len(einwohner),color="red",ls="--")
plt.xticks(rotation=90)
plt.show()
['Belgien', 'Bulgarien', 'Tschechien', 'Daenemark', 'Deutschland einschliesslich ehemalige DDR', 'Estland', 'Irland', 'Griechenland', 'Spanien', 'Frankreich', 'Kroatien', 'Italien', 'Zypern', 'Lettland', 'Litauen', 'Luxemburg', 'Ungarn', 'Malta', 'Niederlande', 'Oesterreich', 'Polen', 'Portugal', 'Rumaenien', 'Slowenien', 'Slowakei', 'Finnland', 'Schweden', 'Vereinigtes Koenigreich']
[11467923, 7000039, 10528984, 5799763, 82940663, 1324820, 4904240, 10722287, 46934632, 67028048, 4076246, 61068437, 875898, 1919968, 2794184, 612179, 9772756, 493559, 17423013, 8842000, 37972812, 10276617, 19405156, 2080908, 5450421, 5512119, 10243000, 66647112]