3.5. Fitting und Interpolation#
Aufgabenteil A1#
Aufgabenstellung#
In der Datei messwerte.txt finden Sie 15 Messwerte entsprechend einer leicht verrauschten Normalverteilung. Nutzen Sie numpy.polyfit, um Polynome an die Messwerte zu fitten. Erstellen Sie Fits von Grad 1 bis zur Interpolation bei Grad 14 und plotten Sie diese.
Lösungsvorschlag#
Show code cell content
import matplotlib.pyplot as plt
import numpy as np
data = np.loadtxt('messwerte.txt')
data_x = data[:, 0]
data_y = data[:, 1]
plt.figure(figsize=[14, 18])
for i in range(1, 15):
P = np.polyfit(data_x, data_y, i)
fit_x = np.linspace(-2.5, 2.5, 100)
plt.subplot(5,3,i)
plt.scatter(data_x, data_y, color='C1', label="Messpunkte")
plt.plot(fit_x, np.polyval(P, fit_x), color='C2', label=f'Fit g{i}')
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
plt.grid();
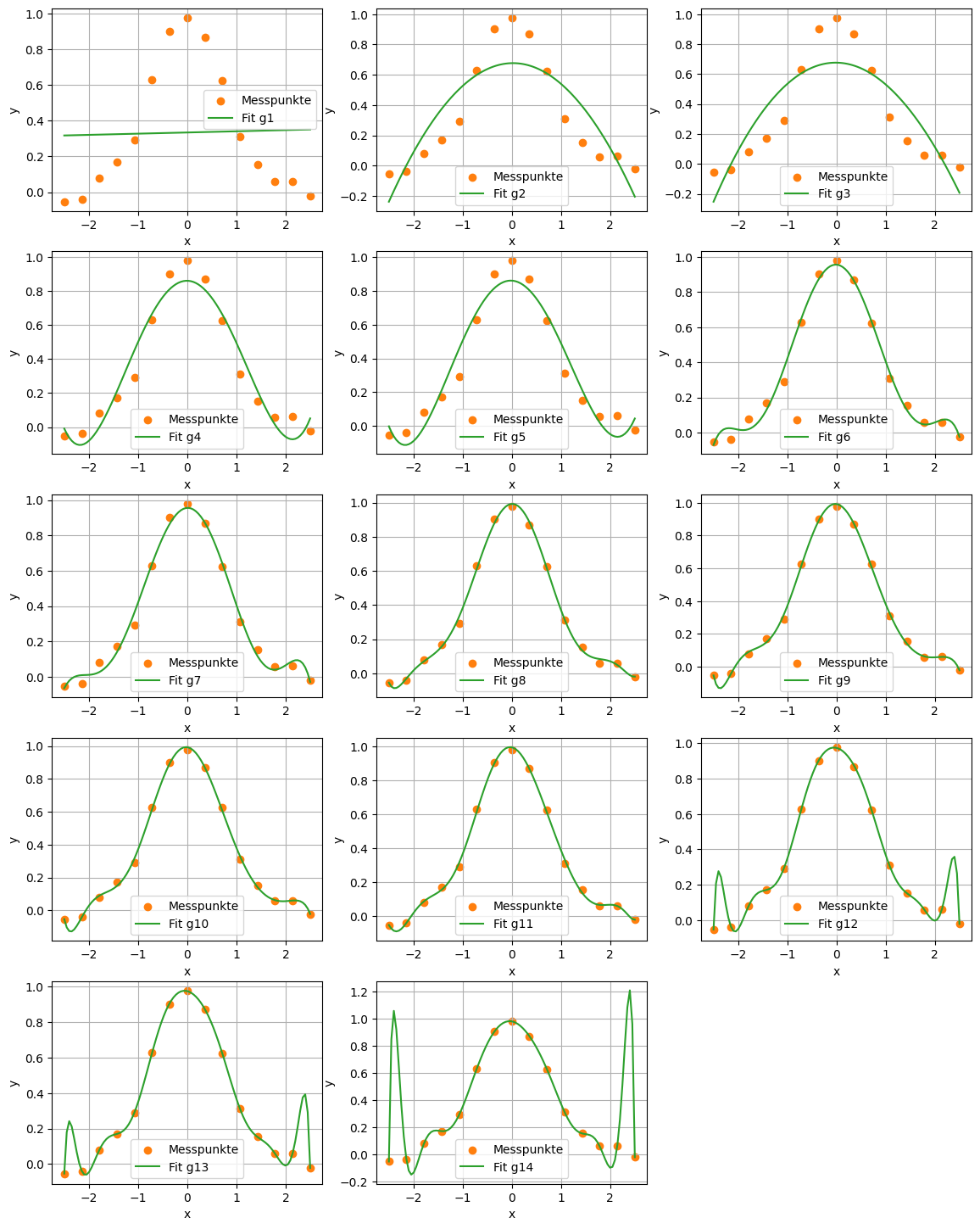
Aufgabenteil A2#
Aufgabenstellung#
Beantworten Sie folgende Fragen:
Warum scheinen manche Fits identisch zu sein?
Wenn man, wie in der Vorlesung beschrieben, belibige Funktionen mit einem Polynom annähren kann und die Messdaten mithilfe einer Funktion erzeugt wurden, wieso wird der Fit ab einem gewissen Grad wieder schlechter?
Wie würden sich mehr Messwerte im gleichen Intervall auf die Fits auswirken?
Aufgabenteil B1#
Aufgabenstellung#
Die Funktion, welche zum Erzeugen der Daten verwendet wurde, ist \(\exp(-x^2)\). Berechnen Sie die L2-Norm aller ihrer Fits. Tragen Sie die Abstände gegen den Grad des Fits auf. Berechnen Sie außerdem den Abstand zwichen den Messwerten und der ursprünglichen Funktion und tragen Sie das Ergebniss als Gerade in ihren Fit ein. Fitten Sie die gleichen Daten ein weiteres Mal, diesmal jedoch mit logarithmisch aufgetragenem Abstand. Ignorieren Sie hierbei die Interpolation.
Lösungsvorschlag#
Show code cell content
# Bestimmung der L2-Norm
def l2_norm(y, func_y):
return np.sum((y-func_y)**2)
norm_fits = []
for i in range(1,15):
P = np.polyfit(data_x, data_y, i)
norm_fits.append(l2_norm(data_y, np.polyval(P, data_x)))
norm_func = l2_norm(data_y, np.exp(-(data_x)**2))
plt.figure(figsize=[10,5])
plt.subplot(1,2,1)
plt.xlabel('Polynomgrad')
plt.ylabel('L2-Norm')
plt.grid()
plt.plot(list(range(1, 15)), norm_fits)
plt.plot([1,14],[norm_func, norm_func]);
plt.subplot(1,2,2)
plt.yscale('log')
plt.xlabel('Polynomgrad')
plt.grid()
plt.plot(list(range(1, 14)), norm_fits[0:-1])
plt.plot([1,14],[norm_func, norm_func]);
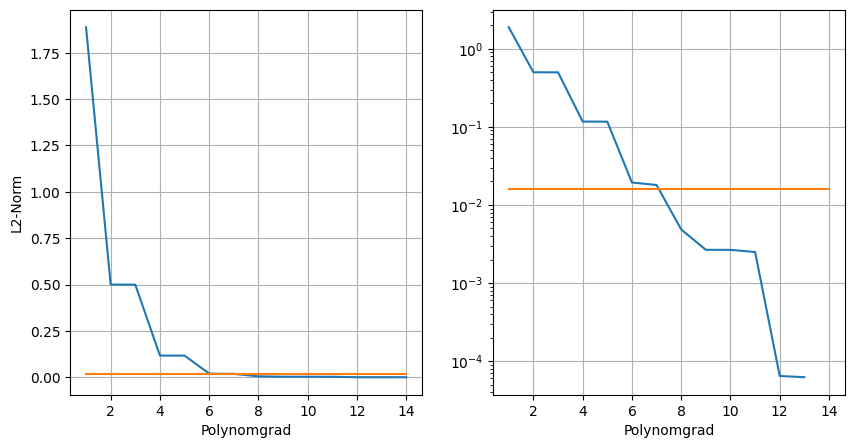
Aufgabenteil B2#
Aufgabenstellung#
Beantworten Sie folgende Fragen:
Wann ist eine logarithmische Darstellung von Daten sinnvoll?
Wieso haben die Plots Plateaus?
Wieso ist es sinnvoll, die Interpolation beim logarithmischen Plot wegzulassen?
Lösungsvorschlag#
Eine logarithmische Darstellung von Daten ist oft dann sinnvoll, wenn diese auf mindestens einer Achse mehrere Größenordnungen umfassen und Details in den kleineren Größenordnungen von Bedeutung sind. Wie in den Plots von Aufgabenteil B1 zu sehen, lassen sich so auch bei höheren Polynomgraden Details ablesen, die in dem linearen Plot verloren gegangen sind.
Die Plateaus korrespondieren mit der Ähnlichkeit der zugehörigen Fits (siehe Aufgabe A2.1).
Da die L2-Norm zwischen der interpolierten Funktion und den Daten bis auf einen numerischen Rundungsfehler Null ist, führt dies zu einem Problem mit der logarithmischen Darstellung, da die Null in dieser nicht dargestellt werden kann. Und auch wenn die Norm nicht ganz Null ist, ist sie um viele Größenordnungen kleiner als die Nrom zwischen vorherigem Grad und Daten, was beim Plotten wieder zu einem Verlust von sichtbaren Details führen würde.